The Problem With Fragmented Agent Infrastructure
As large language models have shifted from conversational assistants toward autonomous agents, the tooling built to support them has not kept pace. Existing agentic infrastructure remains fragmented across three distinct problem areas: evaluation, data management, and agent evolution [1]. Teams working on production agents typically stitch together separate systems for each function, which makes it difficult to discover risks in a systematic way and nearly impossible to improve models through a continuous feedback loop. The absence of integrated infrastructure is particularly acute for tasks that require long-horizon decision making, tool use, and direct interaction with real environments, all of which generate complex, multi-step trajectories that existing pipelines were not designed to handle end-to-end [1].
What Safactory Is
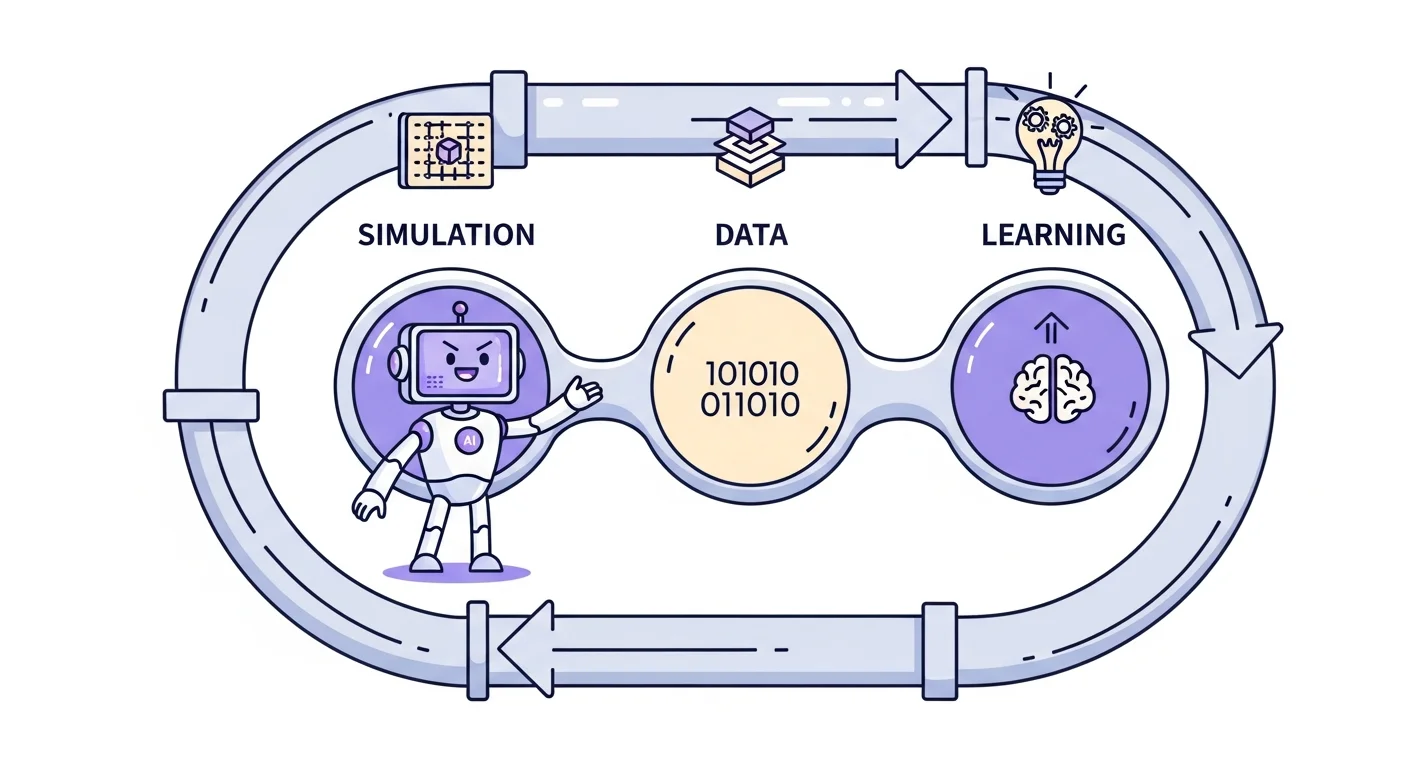
Safactory, short for Scalable Agent Factory, is a framework built to address those gaps by coupling simulation, data handling, and model improvement into a single system. The authors describe it as infrastructure for trustworthy autonomous intelligence, a term they use to signal that safety and reliability are design constraints rather than afterthoughts. At its core, Safactory consists of three tightly coupled platforms that share data and coordinate operations, allowing trajectory generation, storage, and model updates to occur within one unified environment [1].
How the Three Platforms Work Together
The first component is the Parallel Simulation Platform, which is responsible for trajectory generation. It runs agent episodes in parallel, producing the raw behavioral data that feeds the rest of the system. The second component is the Trustworthy Data Platform, which handles trajectory storage and experience extraction. Rather than simply archiving raw outputs, this platform processes trajectories to isolate the experiences most relevant to model improvement. The third component is the Autonomous Evolution Platform, which consumes that processed data to drive model updates through asynchronous reinforcement learning and on-policy distillation [1].
Data flows in one direction through this stack during normal operation. The simulation platform generates trajectories, the data platform filters and structures them, and the evolution platform uses the resulting experiences to update the agent model. Updated models are then redeployed into the simulation platform, closing the loop.
The Closed-Loop Evolution Pipeline
The reinforcement learning mechanism at the heart of Safactory is asynchronous, meaning that model updates do not require the simulation environment to pause. Agents continue generating trajectories while the evolution platform processes earlier batches, which allows the system to operate continuously rather than in discrete training rounds. On-policy distillation complements this by allowing knowledge from higher-performing agent behaviors to transfer into the model being trained, using trajectories that reflect the current policy rather than older, off-policy data [1]. Together, these two mechanisms are intended to support continuous model improvement without the bottlenecks that arise when simulation and training are decoupled.
Intended Use Cases and Target Adopters
Safactory is designed for research and production contexts where agents must operate over extended task horizons, use external tools, and interact with real environments rather than static benchmarks [1]. The framework targets teams building next-generation autonomous agents who need infrastructure that can both surface failure modes systematically and improve models in response to those findings. The closed-loop design makes it particularly relevant for iterative agent development, where repeated cycles of evaluation and retraining are standard practice.
Key Claims and Open Questions
The authors claim that Safactory is the first framework to propose a unified evolutionary pipeline for trustworthy autonomous intelligence [1]. That claim rests on the combination of simulation, data management, and reinforcement learning-based evolution within a single integrated system, which the authors argue has not previously been assembled in this form.
However, the publication is described as a report rather than a peer-reviewed empirical study, and the source material does not include benchmark results, ablation studies, or comparisons against existing agent training frameworks. The performance characteristics of the Parallel Simulation Platform at scale, the quality filtering methods used by the Trustworthy Data Platform, and the convergence behavior of the asynchronous reinforcement learning loop all remain unvalidated in the available documentation. Independent replication and empirical evaluation have not yet been reported.
FAQ
Q. Does Safactory support off-policy reinforcement learning, or is it restricted to on-policy methods? The report describes the Autonomous Evolution Platform as using asynchronous reinforcement learning combined with on-policy distillation [1]. The documentation does not specify whether off-policy algorithms are supported as an alternative configuration.
Q. What types of environments does the Parallel Simulation Platform support? The authors describe Safactory as designed for real environment interaction and tool use, but the report does not enumerate specific environment APIs, simulators, or integration standards that the platform is compatible with [1].
Q. Has Safactory been benchmarked against existing agent training frameworks? No benchmark comparisons appear in the published report [1]. The document presents the system architecture and its design rationale without empirical performance data or head-to-head evaluations.
Q. Is Safactory available as open-source software? The report does not include a code repository link or specify a licensing model. Availability of the implementation has not been confirmed in the published material [1].
Q. How does the Trustworthy Data Platform determine which trajectories are suitable for training? The report describes the platform’s function as trajectory storage and experience extraction but does not detail the filtering criteria, quality scoring methods, or annotation processes used to select experiences for the evolution platform [1].
Key takeaways
- Safactory couples three platforms, covering parallel simulation, data management, and reinforcement learning-based evolution, into a single closed-loop agent training system [1].
- Asynchronous reinforcement learning allows model updates to proceed concurrently with trajectory generation, avoiding discrete training pauses.
- On-policy distillation uses trajectories from the current agent policy to transfer higher-performing behaviors into the model under training.
- The authors claim Safactory is the first unified evolutionary pipeline for trustworthy autonomous intelligence, though no peer-reviewed empirical validation has been published.
- Key implementation details, including environment compatibility, data filtering logic, and scaling behavior, remain undocumented in the available report [1].